

JD hotkey是一个非常好用的京东热点数据分析软件,对任意突发性的无法预先感知的热点请求,都可以进行毫秒级精准探测到。 然后对这些热数据、热用户等,推送到该应用部署的所有机器JVM内存中,以大幅减轻对后端数据存储层的冲击。热数据探测并推送至集群各个服务器, 这些热key在整个应用集群内保持一致性。
软件介绍
JD-hotkey是京东APP后台热数据探测框架,历经多次高压压测和2020年京东618大促考验。在上线运行的这段时间内,每天探测的key数量数十亿计,精准捕获了大量爬虫、刷子用户,另准确探测大量热门商品并毫秒级推送到各个服务端内存,大幅降低了热数据对数据层的查询压力,提升了应用性能。
对任意突发性的无法预先感知的热点请求,包括并不限于热点数据(如突发大量请求同一个商品)、热用户(如爬虫、刷子)、热接口(突发海量请求同一个接口)等,进行毫秒级精准探测到。 然后对这些热数据、热用户等,推送到该应用部署的所有机器JVM内存中,以大幅减轻对后端数据存储层的冲击,并可以由客户端决定如何使用这些热key(譬如对热商品做本地缓存、对热用户进行拒绝访问、对热接口进行熔断或返回默认值)。 这些热key在整个应用集群内保持一致性。
核心功能:热数据探测并推送至集群各个服务器

应用场景
JD-hotkey适用场景:
1、mysql热数据本地缓存
2、redis热数据本地缓存
3、黑名单用户本地缓存
4、爬虫用户限流
5、接口、用户维度限流
6、单机接口、用户维度限流限流
7、集群用户维度限流
8、集群接口维度限流
安装方法
1、安装etcd
在etcd下载页面下载对应操作系统的etcd
2、启动worker(集群) 下载并编译好代码,将worker打包为jar,启动即可。如:
java -jar $JAVA_OPTS worker-0.0.1-SNAPSHOT.jar --etcd.server=${etcdServer}
worker可供配置项如下:

etcdServer为etcd集群的地址,用逗号分隔
JAVA_OPTS是配置的JVM相关,可根据实际情况配置
threadCount为处理key的线程数,不指定时由程序来计算。
workerPath代表该worker为哪个应用提供计算服务,譬如不同的应用appName需要用不同的worker进行隔离,以避免资源竞争。
3、启动控制台
下载并编译好dashboard项目,创建数据库并导入resource下db.sql文件。 配置一下application.yml里的数据库相关和etcdServer地址。
启动dashboard项目,访问ip:8081,即可看到界面。
其中节点信息里,即是当前已启动的worker列表。
规则配置就是为各app设置规则的地方,初次使用时需要先添加APP。在用户管理菜单中,添加一个新用户,设置他的APP名字,如sample。之后新添加的这个用户就可以登录dashboard给自己的APP设置规则了,登录密码默认123456。

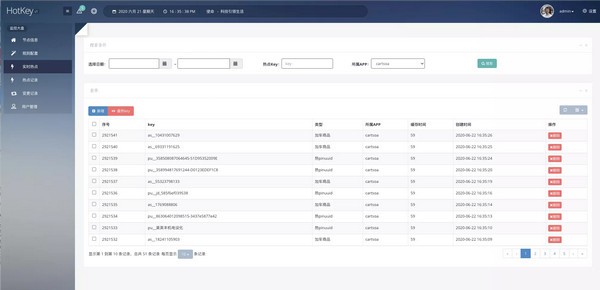
如图就是一组规则,譬如其中as__开头的热key的规则就是interval-2秒内出现了threshold-10次就认为它是热key,它就会被推送到jvm内存中,并缓存60秒,prefix-true代表前缀匹配。那么在应用中,就可以把一组key,都用as__开头,用来探测。
4、client端接入使用
引入client的pom依赖。
在应用启动的地方初始化HotKey,譬如
@PostConstruct public void initHotkey() { ClientStarter.Builder builder = new ClientStarter.Builder(); ClientStarter starter = builder.setAppName("appName").setEtcdServer("http://1.8.8.4:2379,http://1.1.4.4:2379,http://1.1.1.1:2379").build(); starter.startPipeline(); }
其中还可以setCaffeineSize(int size)设置本地缓存最大数量,默认5万,setPushPeriod(Long period)设置批量推送key的间隔时间,默认500ms,该值越小,上报热key越频繁,相应越及时,建议根据实际情况调整,如单机每秒qps10个,那么0.5秒上报一次即可,否则是空跑。该值最小为1,即1ms上报一次。
注意:
如果原有项目里使用了guava,需要升级guava为以下版本,否则过低的guava版本可能发生jar包冲突。或者删除自己项目里的guava的maven依赖,guava升级不会影响原有任何逻辑。
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>28.2-jre</version> <scope>compile</scope> </dependency>
有时可能项目里没有直接依赖guava,但是引入的某个pom里引了guava,也需要将guava排除掉。
常见问题
1、worker挂了怎么办
client根据worker的数量对key进行hash后分发,同一个key一定会被发往同一个worker。譬如4台,挂了一台,key就自动hash到另外3台。那么这个过程中,就会丢失最多一个探测周期内的所有发来的key,譬如2秒10次算热,那么就可能全部被rehash,丢失这2秒的数据。
它的影响是什么呢?我要不要去存下来所有发来的key呢?很多人都会问的问题。
首先挂机,那是极其罕见的事件,即便挂了,对于特别热的key,完全不影响,hash丢几秒,不影响它继续瞬间变热。对于不热的key,它挂不挂,它也热不了。对于那些将热未热的,可能会这次让它热不起来,但没有什么影响,业务服务完全可以吃下这个热key。而加上一堆别的组件如存储、worker间通信传输key等,它的复杂度,性能都会影响很大。
所以它挂了对系统没有任何影响
2、为什么全部要worker汇总计算,而不是客户端自己计算
首先,客户端是会本地累加的,在固定的上报周期内,如500ms内,本地就是在累加,每500ms批量上报给worker一次。如果上报频率很高,如10ms一次,那么大概率本地同一个key是没有累加。
有人会说,把这个间隔拉长,譬如本地计算3秒后,本地判定热key,再上报给其他机器。那么这种场景首先对于京东是不可行的,哪怕1秒都不行。譬如一个用户刷子,它在非常频繁地刷接口,一秒刷了500次,而正常用户一秒最多点5次,它已经是非常严重的刷子了。但我们本地还是判断不出来它是不是刷子。为什么?机器多。
随便一个app小组都有数千台机器,一秒500次请求,一个机器连1次都平均不到,大部分是0次,本地如何判断它是刷子呢?总不能访问我一次就算它刷吧。
然后抢购场景,有些秒杀商品,1-2秒就没了,流量就停了,你本地计算了3秒,才去上报,那活动已经结束了,你的热key再推送已经没价值了。我们就要在活动即将开始之前的可能在10ms内,就要该商品被推送到所有client的jvm里去,根本等不了1秒。
3、为什么是worker推送,而不是worker发送热key到etcd,客户端直接监 听etcd获取热key
(1) worker和client是长连接,产生热key后,直接推送过去,链路短,耗时少。如果是发到etcd,客户端再通过etcd获取,多了一层中转,耗时明显增加。
(2) etcd性能不够,存在单点风险。譬如我有5000台client,每秒产生100个热key,那么每秒就对应50万次推送。我用2台worker即可轻松完成,随着worker的横向扩展,每秒的推送上限线性增加。但无论是etcd、redis等等任何组件,都不可能做到1秒50万次拉取或推送,会瞬间cpu爆满卡死。因为worker是各自隔离的,而etcd是单点的。实际情况下,也不止5000台client,每秒也不止100个热key,只有当前的架构能支撑。
4、为什么是etcd,不是zookeeper之类的
etcd里面具备一个过期删除的功能,你可以设置一个key几秒过期,etcd会自动删除它,删除时还会给所有监 听的client回调,这个功能在框架里是在用的,别的配置中心没有这个功能。
etcd的性能和稳定性、低负载等各项指标非常优异,完全满足我们的需求。而zk在很多暴涨流量前和高负载下,并不是那么稳定,性能也差的远。
标签: 源码相关











-
本类热门推荐本类热门标签
-
详情
 Tablesaw (数据可视化工具)官方版v0.38.1
15.26MB / 3分
Tablesaw (数据可视化工具)官方版v0.38.1
15.26MB / 3分
-
详情
 DailyPaper(日报api接口) 绿色版v3.0.7
42MB / 3分
DailyPaper(日报api接口) 绿色版v3.0.7
42MB / 3分
-
详情
 枫叶单本小说系统 免费版v1.0
5.39MB / 3分
枫叶单本小说系统 免费版v1.0
5.39MB / 3分
-
详情
 悟空crm 免费开源版9.0
60.01MB / 3分
悟空crm 免费开源版9.0
60.01MB / 3分
-
详情
 Alternate WebshopEngine Lite 免费版V1.520
1.92MB / 3分
Alternate WebshopEngine Lite 免费版V1.520
1.92MB / 3分
-
详情
 WordPress 官方最新版
9.39MB / 3分
WordPress 官方最新版
9.39MB / 3分
-
详情
 owncloud源码 V10.0.9
51KB / 3分
owncloud源码 V10.0.9
51KB / 3分
-
详情

-
7 简单搜索天气组件













装机必备软件
网友评论