

Accentize Bundle是一款优秀的音效捆绑包,在DeRoom的基础上使用,可帮助用户修复不想要的混响和回声成分。软件会通过智能算法识别房间条件,提供参数以减少或消除信号不希望出现的部分,插件针对语音录制进行了优化,也可与其他信号一起使用。
软件介绍
专业的后期制作插件,捆绑提供三个专业后期制作工具,并将您的对话编辑工作流程提高到一个新的水平。所有插件均实时运行,这使得在聆听结果时轻松微调参数。您最喜欢的DAW中的所有内容都无需切换应用程序!
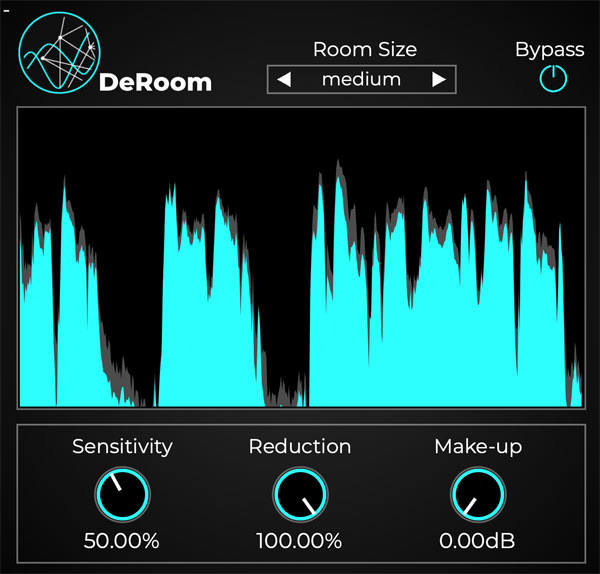
软件功能
一、DeRoom-去除混响
DeRoom是一个基于机器学习的音频插件,可以实时减少或消除混响和房间共鸣。为了能够将直接声音与反射分量分开,已经在许多不同的房间场景中对人工神经网络进行了训练。混响尾巴和回声会被自动检测,然后被精确抑制,或者如果需要的话,将其完全消除。DeRoom非常适合提高在非常混响的环境中录制的语音的质量和清晰度。
二、DeRoom Pro-消除混响
DeRoom Pro是一个基于机器学习的混响去除音频插件,专门用于专业用途。为了能够将直接声音与反射分量分开,已经在许多不同的房间场景中训练了人工神经网络。实时处理方案可在更改参数的同时提供即时反馈,并允许无缝集成到您的工作流中,而无需切换应用程序。
三、DialogueEnhance-语音处理器
DialogueEnhance是一种智能的自动语音处理工具。您可以使用它轻松地提高语音记录的质量,而无需调整许多参数。信号由四个不同的模块处理:降噪,自动均衡,动态降低,响度增强。播客和视频编辑者的有用工具!
四、PreTube-管式饱和器
PreTube是基于机器学习的电子管前置放大器仿真,可为您的乐器或声音录制添加微妙的模拟饱和度。包含的人工神经网络已学会精确模拟实际高端硬件电路的行为。在具有不同特性的三个不同放大器之间进行选择,以找到最适合您的项目的声音。PreTube还是母带链的宝贵补充,可增加模拟深度和温暖感。
五、SpectralBalance-自动均衡器
SpectralBalance是用于对话录音的智能均衡器插件。通过连续分析音频信号,它会自动调整其EQ曲线以校正频谱不平衡,从而获得清晰的中性语音。高效的工作流程使其成为专业人员的非常有用且省时的工具,他们需要处理许多具有不同光谱特征的不同对话。对于具有多个且可能会移动的扬声器的现场应用,自动调整也很方便。
六、VoiceGate-降噪
VoiceGate是一个基于机器学习的音频插件,可用于实时减少语音和人声录音中的噪音。人工神经网络已经接受了100多个小时的音频数据训练,以学习人类语音的特征。该插件可以自动适应各种不同的噪声类型,并让您轻松控制所需的降噪量。
消除混响和共鸣
在理想的世界中,所有录音都将在具有所需特征(混响长度,早期反射,频率响应...)的最佳环境中进行。不幸的是,在许多情况下,这种环境根本不存在或很难提出。在声学上优化录音室是一个复杂且通常非常昂贵的过程,需要大量专家知识。此外,如果您正在进行现场录制,通常根本无法选择或更改设置。本文将概述次优记录环境的主要问题,以及可以采取的一些措施来解决这些负面影响。我们将集中讨论两个主要问题,即共振频率和不想要的混响。
共振频率
共振频率对应于特定波长,该特定波长由于房间的几何形状而被放大。如果波长或波长的倍数恰好适合两个平行表面之间的空间,则将发生所谓的驻波。例如,200hz的窦的波长为1.72米。如果您的录音室恰好恰好具有1.72米(或3.74米)的宽度,并且墙壁是平坦的,反射性的表面,您会在录音中观察到此频率的增强(可能还有其他谐波,例如100hz或400hz) 。消除此问题的物理措施通常是通过安装特定的房间声学元件,将墙壁修改为反射更少或散射更多。如果无法更改房间或已经完成录制,
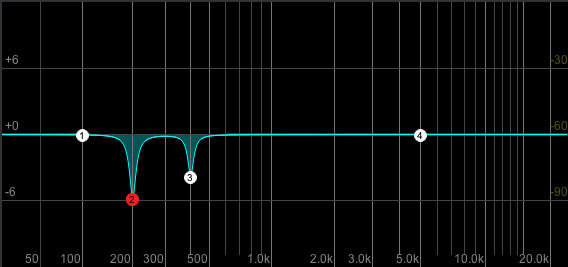
在这里,明显的挑战是通过耳朵识别频率,这需要一定的练习量,但绝对是可行的。通过使用任何参数均衡器并扫过整个频谱,房间的共振将变得很明显,并可以根据需要减少很多。
混响
可能成为问题的第二个效果是房间混响。在每个录音环境中,您都可以想到会有一定程度的混响(除非是在无回音室内进行的混响)。没有任何混响,由于我们的耳朵不习惯于只听直接的声音而没有任何室内反射,因此录制的声音听起来会非常不自然。但是,例如,如果您在一个大型演讲厅中录制演讲,则混响可能会很烦人,并且绝对不利于语音清晰度。与房间共振相反,这里不仅影响单个频率,还影响整个频谱。静态参数均衡器很可能无法解决此问题,因此需要应用其他工具。扩展程序是一种值得一试的插件:
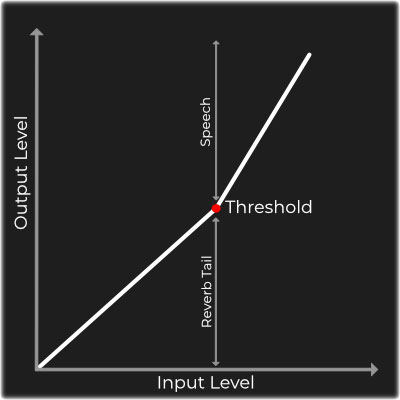
扩展器将放大高于阈值的所有输入电平,而低于该阈值的电平则不受影响。想法是将阈值精确地放置在输入语音的最低水平之下,以便仅语音被放大而混响尾巴不被放大。这样可以提高信噪比,整体信号听起来会更干净。如果您手头有一个多频段扩展器,您甚至可以针对不同的频率调整此过程,以更准确地处理信号频谱。但是,此方法可能会产生一些不希望有的副作用,因为它还会更改整个语音动力学。
模拟硬件仿真的机器学习
在大多数录音棚都采用数字录音解决方案为标准的时代,许多人仍然喜欢在某些情况下使用模拟硬件。如果您问他们为什么您最有可能听到诸如饱和度,深度或温暖或其他花哨的特征之类的术语,以证明使用旧技术而非现代技术是合理的。模拟录音肯定有一些神奇之处,显然在数字世界中并非如此。这种硬件的一些示例是吉他放大器,麦克风前置放大器或录音机。正如人们所期望的那样,对于某些人来说,将数字音频工作站的易用性与物理记录硬件的模拟声音相结合一直是一个目标。例如,
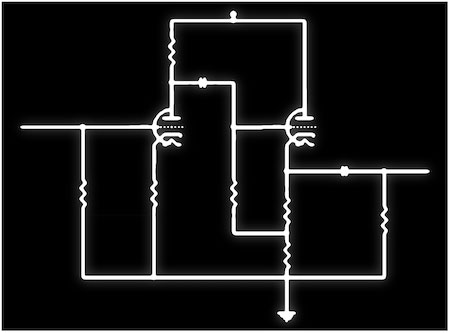
组件化建模
用软件算法仿真硬件的经典方法是精简底层电路并分别对每个组件的属性建模。这意味着所有零件(如电容器,电感器,晶体管或电子管)的行为都将在程序代码中进行分析和重构。然后,可以将这些代码模块以与它们在电路板上的接线相同的方式放在一起。其中一些方法实际上已经接近实际交易,并且清楚地显示了与真实硬件类似的非线性行为。但是,实际上很难对每个小方面进行建模,尤其是对组件之间的频率相关交互进行建模。即使每个组件的所有模拟行为均正确无误,仍然存在许多其他因素,例如导线之间的磁感应或影响声音的充电过程。这些高度复杂的相互作用可以使用微分方程和其他复杂的数学模型来部分描述。为了提高准确性,这些计算可能会越来越完善,这需要大量的技术知识,并且变得非常复杂且计算上很昂贵。

基于机器学习的建模
人工智能技术的使用在几乎所有类型的行业中都在增加,并且已经显示出能够找到许多迄今为止尚未解决的问题的解决方案。如今,机器学习已成为图像处理等领域的标准,其中可以使用人工神经网络构建非常精确的分类器和其他工具。试图将相同的技术应用于音频硬件仿真是一个显而易见的主意,以克服上述人造硬件模型的局限性。与智能组件建模相反,该技术将整个硬件视为一个系统。这很有用,因为它考虑了元素之间的每一个微小交互以及手工制作模型中可能遗漏的其他细节。
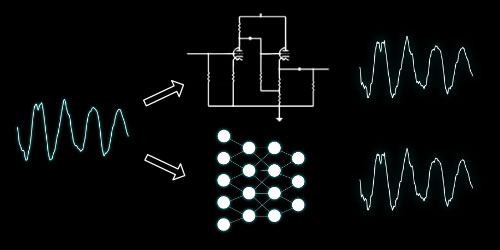
PreTube和PreFET
作为概念的第一个证明,我们挖了一些模拟前置放大器,让网络硬件的输入和输出信号,以了解两者之间的确切映射。此过程称为培训,需要大量示例数据和计算资源。经过一些训练迭代和对原始神经网络拓扑的大量修改,我们能够提出一些非常酷的听起来算法,这些算法显然表现出与其硬件角色模型相同的特征。在这里,最大的限制是所需的计算能力,我们可以将其降低到即使在多个实例中也可以在单个CPU上运行的程度。当然,
标签: 音效插件















-
本类热门推荐本类热门标签
-
详情
 智能电音 (专业VST机架开发软件)正式版v1.0
21MB / 3分
智能电音 (专业VST机架开发软件)正式版v1.0
21MB / 3分
-
详情
 ocenaudio绿色便携版 v3.7.4
39.42MB / 3分
ocenaudio绿色便携版 v3.7.4
39.42MB / 3分
-
详情
 AutoTune pro 中文绿色版v9.10
109.76MB / 3分
AutoTune pro 中文绿色版v9.10
109.76MB / 3分
-
详情
 iZotope RX8 中文版v8.1.0
447MB / 3分
iZotope RX8 中文版v8.1.0
447MB / 3分
-
详情
 Studio One精编版 (附机架)官方中文版V3.5
42.1MB / 3分
Studio One精编版 (附机架)官方中文版V3.5
42.1MB / 3分
-
详情
 Voicemeeter 官方版
76.8MB / 3分
Voicemeeter 官方版
76.8MB / 3分
-
详情
 YAMAHA VOCALOID5 Editor 官方中文版v5.2.0.1
436.4MB / 3分
YAMAHA VOCALOID5 Editor 官方中文版v5.2.0.1
436.4MB / 3分
-
详情



















装机必备软件
网友评论