

易明建模是一键式智能数据建模工具,建模流程完全自动进行。一键式建模,又快又好!无需数据科学家即可建模。传统的手工建模有着诸多的缺点,并且效率很低,比如:探索数据、数据噪音、时间特征、高基数变量、模型需求多、如何有效评估模型、非正态分布、标准化、LR, RF,GBDT…..使用哪种算法、项目周期长、缺失值、参数配置等等。智能建模改变应用模式:业务用户主导,应用过程中随时随地建模。
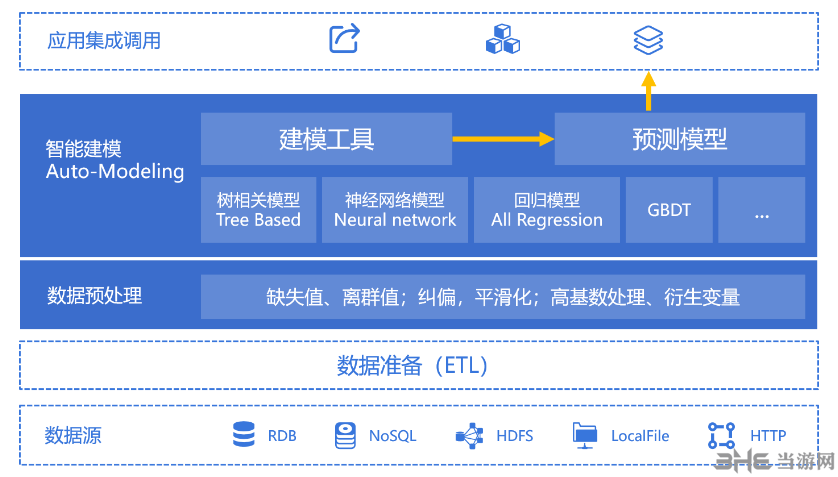
软件功能
【数据源】
1. 本地数据文件
智能建模支持txt、csv等格式的数据文件。
选择文件后,可以定义数据文件的参数配置。
下一步,可以定义变量类型、日期格式和选出状态。
2. 数据库
在数据源窗口中,可以定义JDBC和ODBC两种数据源连接。
【数据探索】
1. 基本特征
导入数据以后,显示了数据的基本特征:
目标变量是Survived(需要用户设置),有12个变量,891条记录。
自动解析了各个变量的类型和推荐的选出状态。
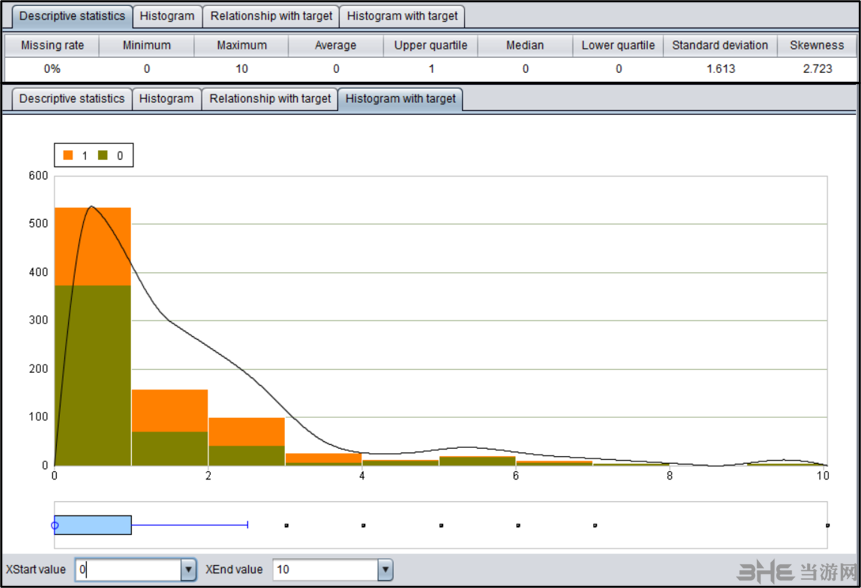
2. 离散变量统计
离散变量包括单值变量、二值变量和分类变量。
缺失率:缺失值在全部数据中的占比。
势:离散变量可取值集合的成员数量。
饼图直观显示了各分类的占比。

【预处理】
1. 自动预处理
智能建模的预处理过程集成在建模的流程中,一键式自动预处理。
2. 预处理报告
建模结束后可以导出模型报告,描述了预处理执行了哪些动作。
3. 预处理流程
(1)检查变量值域
检查并记录所有变量的值域,若测试数据出现训练数据没有的分类或者超出数值范围,进行针对性的处理。
(2)时间日期变量处理
检查所有时间日期型变量,创建若干常用的衍生变量。并检测时间日期变量的关联性,创建多日期联动的衍生变量。
(3)缺失值信息提取
若数据存在缺失值,提取并记录缺失值模式,将缺失值所表现出的行为特征转换为衍生变量加以利用。
(4)缺失值填补
若数据存在缺失值,利用简单或个性化智能算法,填补缺失值。
(5)分类变量降噪
针对分类变量可能存在的噪音,例如极少数分类,异常分类,疑似错误分类等情况,进行针对性处理。
(6)分类变量数值化
将分类变量转换为可正常进行运算的数值型变量。主要方式是dummy variable和平滑化,由算法智能判断。
(7)纠偏
针对部分存在正态性假设的模型,对高偏态变量进行数学变换,使偏度回到0附近,满足模型假设。
(8)异常值处理
探测并识别可能存在的异常值,并进行针对性处理。
(9)变量筛选
以较宽松的门槛,剔除掉对建模无用的变量,降低时间成本和模型复杂度。
(10)标准化/归一化
数据标准化/归一化,消除口径差异。有利于神经网络等模型的寻优求解。
(11)平衡样本
对于二分类数据,若正负样本比例严重不均衡,会按照指定的比例配平,并智能重采样建模。
4. 手动预处理
选择变量
根据变量类型去除一些无关的变量。例如ID和长文本,没有缺失值的单值变量等。
衍生变量
用变量姐妹、配偶数量"SibSp"和 变量父母、子女数量"Parch"相加得到家庭成员数量"Family"。可以看到家庭成员在1-3人时幸存率较高。
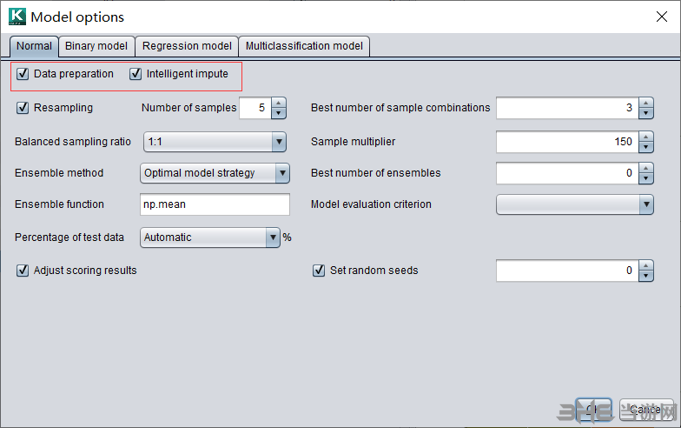
预处理选项
在模型选项中可以定义是否数据预处理和是否智能填补。
如果数据已经进行过预处理,可以取消数据预处理。
智能填补可以更好的对缺失值进行补缺,但是会消耗更多的硬件资源和时间,当数据量很大时不建议智能填补。不勾选时会进行简单填补。
更新内容
python版本升级到3.9
升级依赖包兼容性到最新版
修复ubuntu24.04环境下无法打开建模ide的问题
修复个别模型异常调用cuda的问题
优化性能,修复潜在bug

数据分析是在各行各业都非常重要的环节,通过数据分析工具,可以将有用的信息提取出来,对其进行统计和处理,并且可以数据可视化,从而更加便捷的将其展示出来。那么数据分析软件哪个最好用呢,在这里小编给大家整理了市面上主流的数据分析工具。






















-
本类热门推荐本类热门标签
-
详情
 苏打办公 最新版v2.0.0.1441
16.7MB / 3分
苏打办公 最新版v2.0.0.1441
16.7MB / 3分
-
详情
 ProjeQtOr (项目管理软件)最新版v9.0.2
50.67MB / 3分
ProjeQtOr (项目管理软件)最新版v9.0.2
50.67MB / 3分
-
详情
 DzzOffice开源版 最新源码版v2.02.1
19.22MB / 3分
DzzOffice开源版 最新源码版v2.02.1
19.22MB / 3分
-
详情
 Draw.io Desktop流程图绘制软件 便携免安装版v13.9.5
70.52MB / 3分
Draw.io Desktop流程图绘制软件 便携免安装版v13.9.5
70.52MB / 3分
-
详情
 project2016 官方版
540MB / 3分
project2016 官方版
540MB / 3分
-
详情
 华望云会议视频软件 官方版v3.6.1.8
22.76MB / 3分
华望云会议视频软件 官方版v3.6.1.8
22.76MB / 3分
-
详情
 极速Office2019 电脑版v1.0.9.0
80.83MB / 3分
极速Office2019 电脑版v1.0.9.0
80.83MB / 3分
-
详情




















装机必备软件
网友评论